‘Next App router에서 RSC와 RCC가 어떤 방식으로 렌더링 되는거지?’ 를 알기 위해 RSC란 무엇인가?
React Server Component(RSC)란 무엇인가?
React v18에 나온 개념으로 React components를 오직 Server에서만 실행되는 components이다.
이게 왜 필요한 걸까?를 알기 위해서는 RSC가 나오기 이전 방식들이 가지고 있는 문제점을 알아야 한다.
1. RSC가 나오게 된 배경
먼저 렌더링의 역사를 가볍게 살펴보자
Server Side Template의 문제점 (CSR이 나오게 된 배경)
초기에는 서버에서 HTML을 모두 만들어서 넘겨줬다.
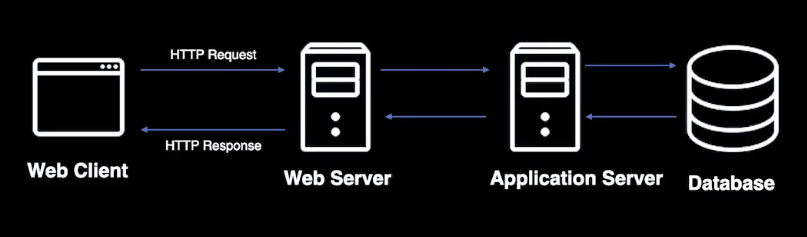
web server는 없어두 됨
특징
- JSP와 같은 다양한 템플릿으로 server에서 HTML을 생성해서 보내줬다.
- 브라우저에서 HTML을 렌더링 후 JS를 client에서 실행하며 인터렉션 처리를 해줬다.
문제점
- ajax 요청에 따른 Client에서 렌더링을 추가하는 것 같은 동적인 기능 구현(더보기, 무한 스크롤, …)에는 뷰 로직이 server side, client side에 각각 구현되어야 해서 불편했다. → 인터렉션이 복잡해질수록 난이도가 수직 상승한다! (DX 극악)
- 결국 server에서 데이터 패칭 후 HTML이 완성되면 보내주기 때문에 유저가 빈화면을 보는 시간이 길어진다 (UX 하락, FID감소)
(사실 전 안 겪어봐서 잘 모르겠어요,,)
Client Side Rendering의 문제점 (SSR이 나오게 된 배경)
위의 문제점을 해결하고자 브라우저 성능 향상과 JS스팩 향상이라는 시대적 배경와 맞물려 rendering을 모두 client에서 하도록 하는 움직임이 생겼다.
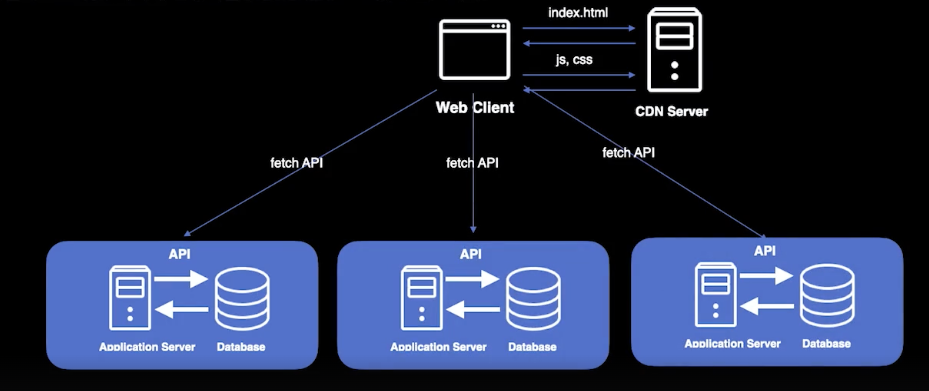
익숙하쥬?
왔다리 갔다리
특징
- 웹 애플리케이션에는 HTML, CSS, JS만 있고 server에서 API 형태로 데이터를 내려준다.
- Client Application에는 정적인 파일들만 있기 때문에 개념적으로는 Static Web Site와 비슷하다 → 덕분에 app server없이 CDN에 배포를 할 수 있다.
- 기존에 server side에서 해주던 URL에 따른 라우팅 처리를 Client에서 처리한다 (이걸 바로 SPA라고 한다.)
- 그래서 배포 이후 내부 URL로 접속하면 CDN에는 해당하는 경로에 index.html이 없기 때문에 404에러가 뜬다. → 그래서 배포시 404 페이지를 루트로 보내주는 처리가 필요하다
장점
- app server가 없기 때문에 배포 속도가 빠르다
- app server가 없기 때문에 우리가 트래픽 대응을 안해줘도 된다.(보통 CDN이 해준다.)
- API 호출이 오래걸려도 일단 HTML이 있기때문에 사용자들에게 “로딩 중”을 띄울 수가 있다. (UX 향상)
문제
- 어떤 페이지를 접속해도 동일한 CDN에서 index.html을 보내주기 때문에 meta:og 태그 관련 문제가 생긴다(SEO 취약)
- 그래서 크롤러/봇 이 보기에 빈페이지로 보인다.
- 사실 이거는 lambda edge, firebase functions등으로 보완이 가능하다 (해결말고 보완!)
- 그래서 크롤러/봇 이 보기에 빈페이지로 보인다.
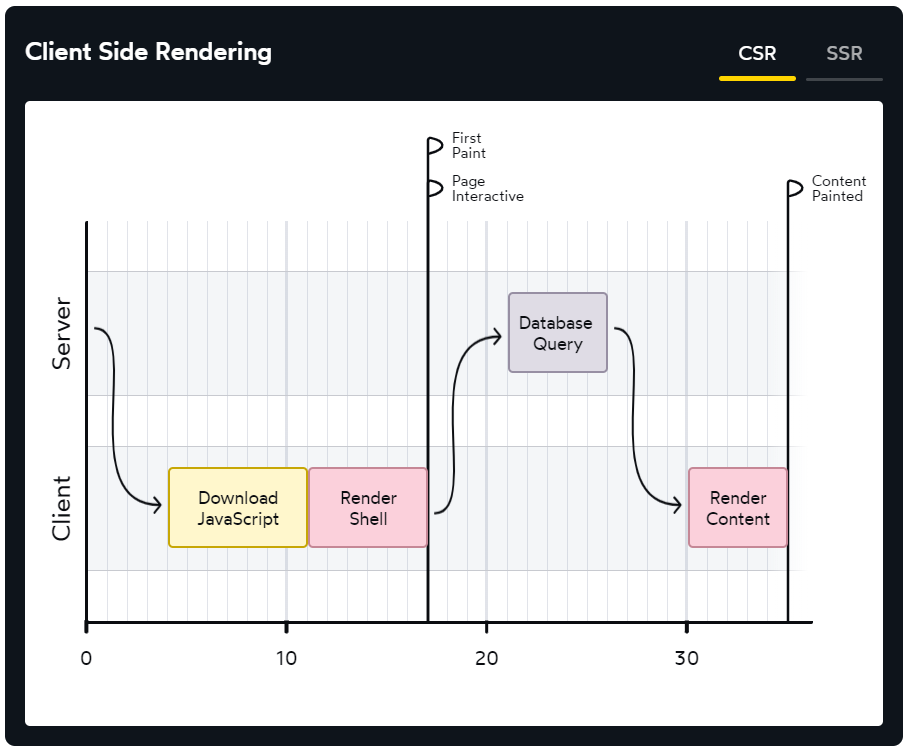
- 초기에 빈 HTML을 내려받고 JS 번들을 다운받아 JS 코드가 실행되며 화면이 채워지기 때문에 초기에 실행해야하는 JS양이 많아진다. 따라서 첫 화면 렌더링 시간이 길어진다 (UX 하락)
- SST같은 경우 페이지 이동 시 브라우저가 새로고침 되기 때문에 메모리가 누수되어서 초기화해줘서 큰 문제가 없는데 SPA는 페이지 이동 시 새로고침이 아니라 JS로 새로 그려주는 것이기 때문에 메모리가 그대로 남아있어서 메모리 누수에 취약하다
- 메모리 누수로 인해 화면을 켜놓고 있으면 점점 느려질 수 있다. (UX 하락)
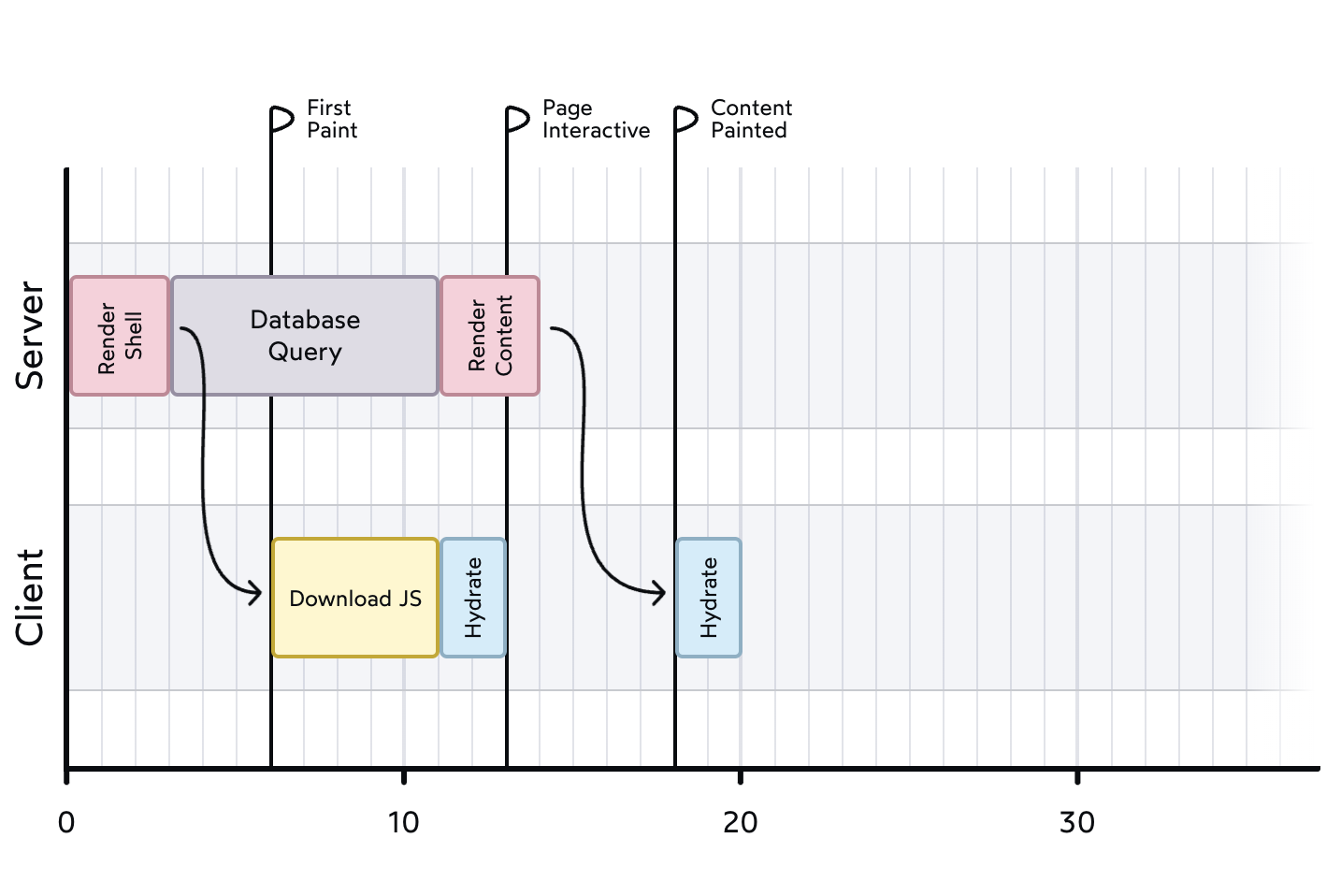
Server Side Rendering의 문제점
node.js의 발전으로 server와 client가 같은 언어로 작업이 가능해졌다. 따라서 SST의 가장 큰 문제점이었던 뷰로직이 따로따로 있는것을 공유할 수 있게 되면서 rendering을 다시 server에서 하자는 움직임이 생겼다.
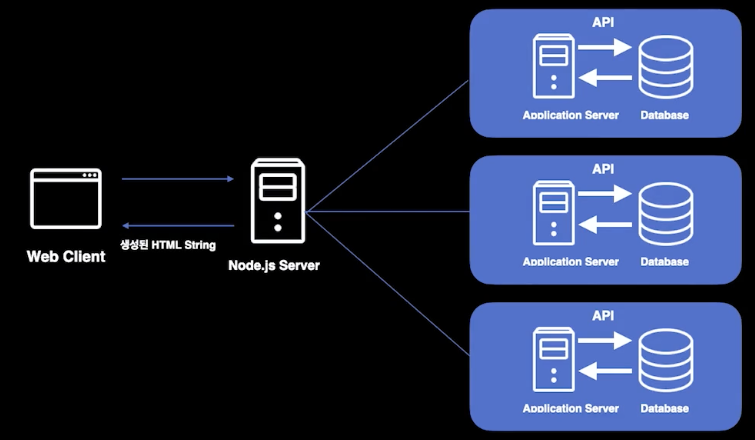
이 그림은 프리패칭이 포함된 SSR입니다.
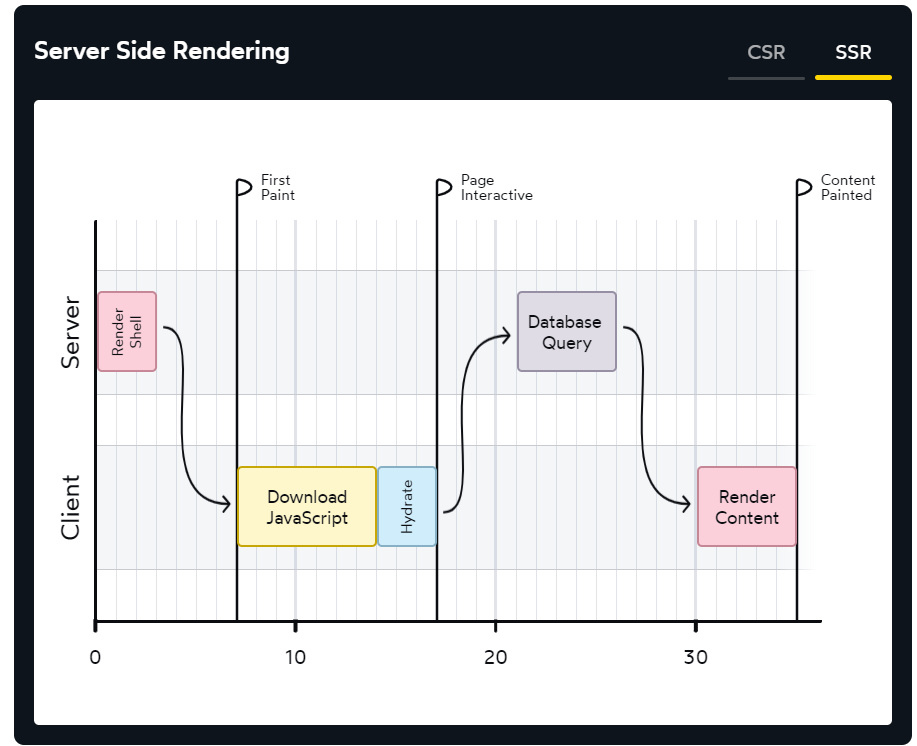
왔다리갔다리 하긴 하는데 일단 뭔갈 보여주고 하쥬?
특징
- client가 server에 요청을 하면 node 서버에서 HTML을 만들어 준다.
- 만든 HTML과 JS번들을 client로 보내주면 브라우저에서 렌더링해준다.
- client에서 정적인 HTML에 JS를 맵핑하는 hydration 과정을 거쳐 동적인 HTML로 만들어준다.
장점
- 미리 HTML을 만들기 때문에 meta:og 태그등을 사용할 수 있으면서 SEO가 향상된다.
- Shell(데이터나 인터렉션이 필요없는 부분)부분을 미리 HTML로 만들어 보내면서 FCP가 향상된다.
+ 추가
추가적으로 Next의 page router같은 경우는 DataBaseQuery부분도 server에서 실행하며 데이터를 담은 HTML을 만들어 내려줬다. (뒤에 또 나와융)
문제
- 결국 HTML과 JS 번들을 내려받기 때문에 Client에서 다운받는 양이 증가한다 (성능 하락)
- server에서 HTML을 만들고 JS을 내려받는 과정 → 하이렉션 이후 데이터를 요청하는 과정 → 다시 데이터 패칭 이런식으로 네크워크 왕복 과정을 거치게 됨 (성능 하락)
- HTML을 내려받고 hydrate하기 전까지의 시간동안은 유저의 인터렉션에 반응하지 못한다 (UX 하락)
RSC가 나오기 전까지의 과정들을 살펴보았다. SSR의 문제를 해소하기 위해서 ISR이라는 렌더링 방식도 나오는 등 여러가지 움직임이 있었지만 근본적인 해결이 아닌 문제를 완화시키는 형태이다.
결국 이러한 문제를 해소하기 위해 RSC가 탄생했다.
그러면 RSC는 어떤 문제를 어떻게 해결해 줬을까?
2. RSC가 해결한 문제
React v18에서 나온 RSC는 위의 문제를 어떻게 해결했는지 살펴보자.
1. 결국 HTML과 JS 번들을 내려받기 때문에 Client에서 다운받는 양이 증가한다 (성능 하락)
RSC는 server에서’만’ 동작하는 react component이다. server에서 실행된 RSC는 RSC Payload라는 직렬화된 JSON포맷의(JSON은 아님!) Stream 형태의 특수한 데이터 형식을 렌더링한다
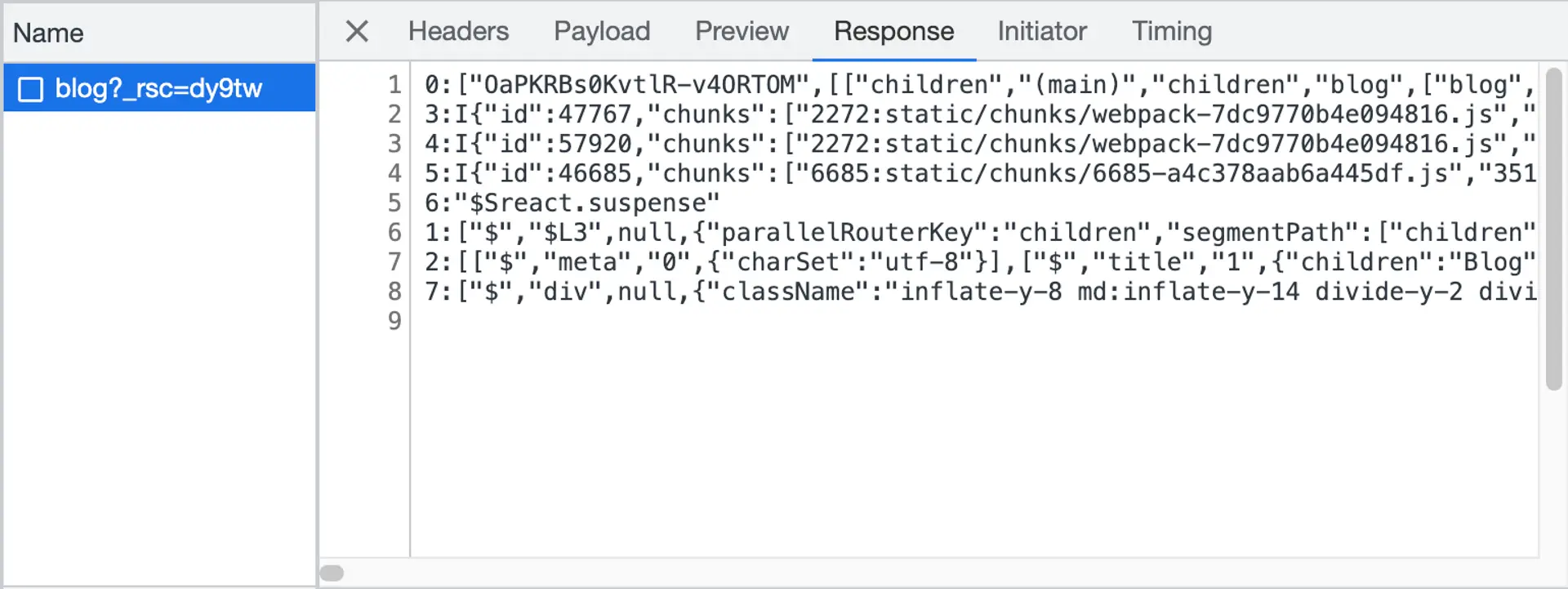
아-찔⭐️
이 안에는 RSC가 실행되면서 JS코드가 실행된 결과값이 담겨있다. 이때 RCC는 실행되지 않고 RCC가 있다~ 라는 placeholder를 만들어 놓으며 넘어간다. 그리고 Client에서 이거를 채워주는 것이다.
이러한 RSC가 만들어주는 React tree를 시각화해보면 아래와 같다
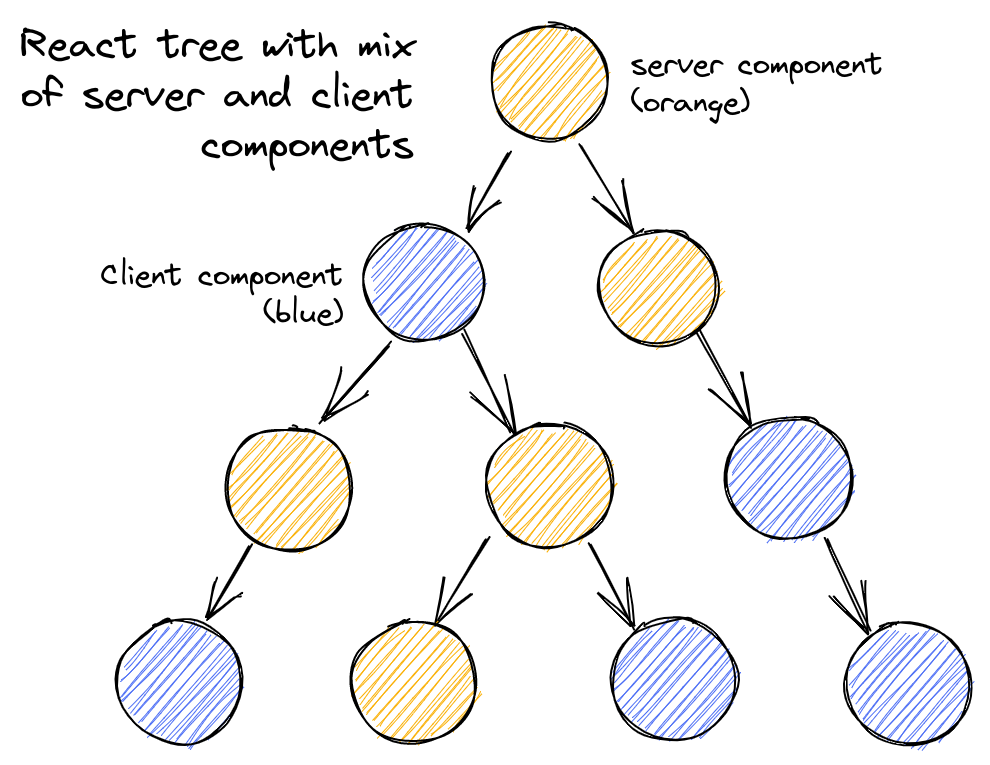
위에서 언급했듯 이 tree는 직렬화된 JSON 포맷인 RSC Payload이다. 그리고 그 안에 RCC 같은 경우 RSC에서 실행한 결과를 넣어놓는게 아닌 RCC라는 표시를 하는 placeholder로 남겨놓는 것이다.
그 이유가 RCC는 함수다. 함수는 직렬화를 할 수가 없다. 따라서 이를 “module reference” 라고 하는 새로운 타입을 적용하고 컴포넌트의 경로를 명시 후 넘어간다.(Client에서 해석할 수 있도록 표시만 해놓는 것임)
{
$$typeof: Symbol(react.element),
type: {
$$typeof: Symbol(react.module.reference),
name: "default", //export default를 의미
filename: "./src/ClientComponent.js" //파일 경로
},
props: { children: "some children" },
}
이렇게 만들어진 Stream 형태의 RSC Payload를 반환하여 함께 다운 받은 JS 번들과 hydration 후 DOM을 그려준다.
또 혁신인게 있는게 기존 RSC와 RCC의 경계가 일반적으로 작성하던 트리 형태랑 다르다.
‘use Client’를 쓰는 순간 Client boundary가 생기고 하위 컴포넌트들은 모두 RCC가 된다.
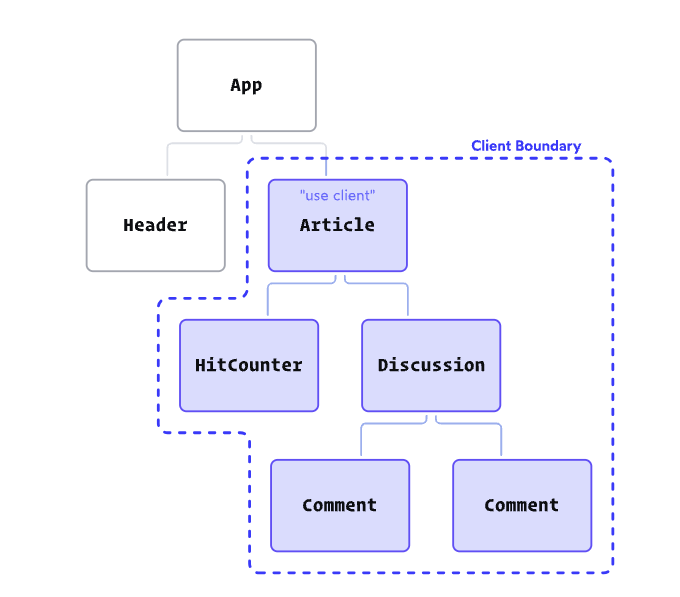
근데 RCC안에 RSC를 넣고 싶으면 어떻게 해야되냐? RCC안에 {children} 을 만들고 RSC에서 RCC를 호출 한 후 내부에 RSC를 넣어주는 것이다.
const ServerComponent = () => {
return (
<RCC>
<RSC1 />
<RSC2 />
</RCC>
);
};
이런 구조인 것이다.
트리상으로는 RCC가 RSC보다 높지만 Client Boundary에서 중요한 것은 부모/자식 관계가 아니다.
중요한 것은 “어디서 호출”되었는가 이다!!! 위에 설명을 다시 기억해보면 RSC Payload를 만들 때 RCC는 표시만 해두고 넘어간다고 했다. 그렇게 넘어가고 RSC1, 2 코드가 실행되는 것이다.
RSC1, RSC2가 트리 상으로는 자식이지만 그게 중요한게 아니라 RSC에서 호출되었다는게 중요한 것이다.
Client Boundary는 단순 트리의 부모/자식 구조가 아니라 호출된 곳으로 결정된다
-
예시 Next에 TanStackQuery세팅하는 것을 생각해보면 RSC인
root Layout을 RCC인QueryClientProvider로 감싸준다. 일반적으로 생각하면 RCC로 감쌌으니깐 내부가 모두 RCC가 되야 하지만 그래서QueryClientProvider내부에 RSC가 존재할 수 있으며 하위의 RCC에서QueryClientProvider의queryClient를 접근할 수 있는것이다.'use client' const Provider = ({children}: Props) => { const queryClient = new QueryClient({ ... }); return ( <QueryClientProvider client={queryClient}> {children} </QueryClientProvider> ); }; export default Provider;const RootLayout = ({children}: Props) => { ... return ( <html lang="en"> <body> <Provider> {children} </Provider> </body> </html> ); }; export default RootLayout;
(우리가 Props Drilling를 피하기 위해 합성 컴포넌트를 구현할 때와 닮았다.)
2. 네크워크 왕복 과정이 발생 (성능 하락)
기존에 shell을 그린 HTML과 JS 번들을 내려받아 hydrate 이후 데이터 패칭을 위해 다시 server에 요청을 해야하는 왕복 과정이 불가피했다. 하지만 데이터 패칭까지 한 후 content가 담긴 RSC Payload를 반환하기 때문에 네트워크 왕복과정을 없앨 수 있었다.
여기서 의문을 가질 수 있다.
결론부터 말하자면 반은 맞고 반은 틀리다.
Next page router에서 시대에 앞서나간 방식으로 데이터 패칭을 포함함 SSR를 할 수 있었다.(갓 vercel…)
하지만 page router에서 데이터 패칭하는 방법을 돌이켜보면 최상단인 page에서 초기 렌더링 시 getServerSideProps로 데이터패칭을 진행하고 page에 Props로 내려주었다. 그리고 내부 컴포넌트에서 사용하고 싶을때는 props로 내려줘야 했다. 즉, 페이지 단위에서만 데이터 프리패칭을 할 수 있었던 것이다.
+ 추가 생각
GraphQL의 장점으로 under fetching, over fetching 등이 있지만 이를 통해 사용하는 곳에서 필요한 데이터만 불러와 쓸 수 있는게 가장 큰 장점이라고 생각하다(멘토님이 알려주셨던!!)
따라서 pate router와 RSC를 사용한 App router를 비교하자면
Next 12 page router -> REST API Next 13 App router -> GraphQL
이런 느낌이다.
3. HTML을 내려받고 hydrate하기 전까지의 시간동안은 유저의 인터렉션에 반응하지 못한다 (UX 하락)
이건 사실 RSC만드러 해결한 문제는 아니고 Suspense를 통한 Steram HTML과 결합해서 문제점을 보완한 것이다. 결국 스트리밍 방식으로 각각의 컴포넌트를 조각조각(chunk) 받기 때문에 완성된 것부터 hydrate 시켜 유저가 체감하는 인터렉션이 안되는 시간을 줄인 기법이다.
이것도 개쩌는 포인트가 결론적으로 말하자면
hydration의 기본값은 부모 → 자식 / 코드의 위 → 아래 순으로 진행이 되는데 이때 유저의 인터렉션이 생긴다면 현재 hydration은 멈추고 인터렉션인 생긴 chunk부터 hydrate를 진행한다. 원리가 너무 궁금하다ㅜ(진짜 어케했누…)
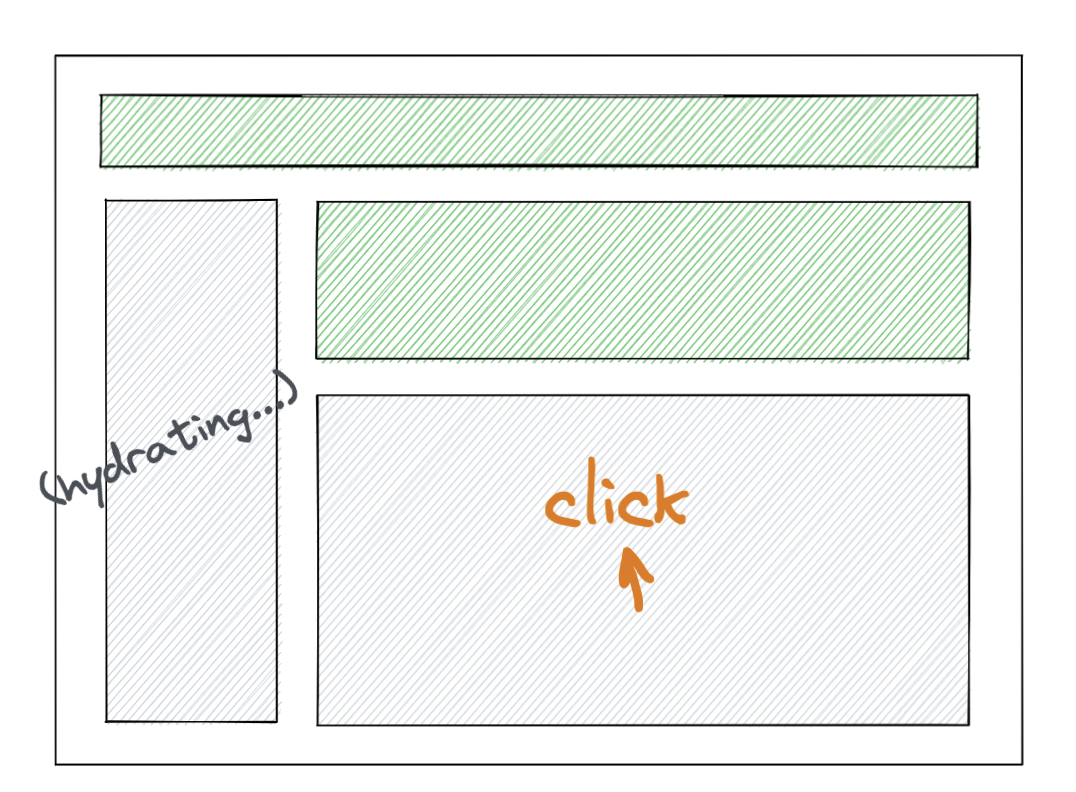
원래 순서에서 유저 액션이 생기면?
일케 순서가 바뀜
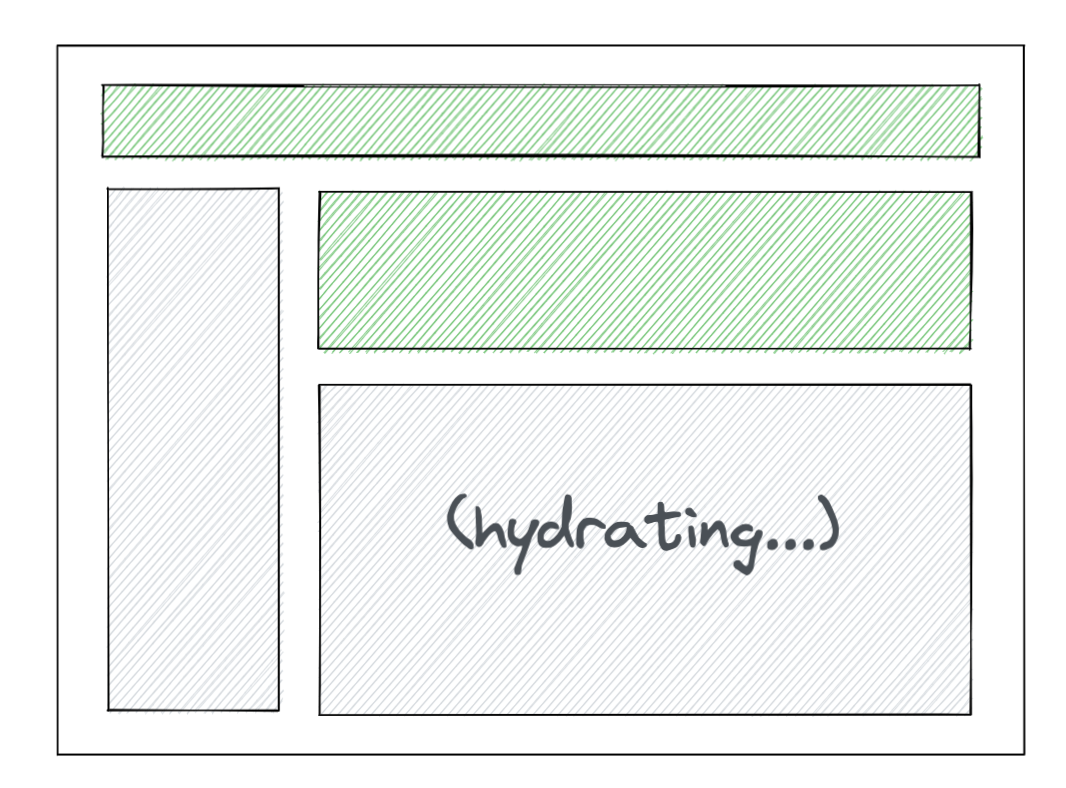
이 두개의 아키텍터를 결합하면 아래와 같이 그림같은 데이터 흐름과 화면을 그려줄 수 있다.(FCP, TTI, LCP 모든면에서 상승된다.)
이러한 해결방법으로 갖게된 RSC의 장점을 정리해보면 아래와 같다.
3. RSC의 장점
No Client-Server Waterfalls
깔-끔
server API 호출 없이 파일 시스템, DB 등에 접근이 가능하기 때문에 가능한 일이다. 또한 Next page router와는 다르게 component 단위로 데이터 패칭을 할 수 있기 때문에 Props drilling으로부터도 해방되었다!!
- DB접근을 client가 보면 어떻게 하냐!! 라는 보안적 문제를 걱정 할 수 있지만 위에서 말했든 RSC는 server에서’만’ 실행된다. 즉, client는 RSC 코드를 볼 수 없다^^ (극-뽁)
Zero-Bundle-Size components
다시 말하자면 RSC는 server에서’만’ 실행된다. 따라서 RSC 코드를 Client가 내려받지 않는다. 즉, 코드에 실행하는데 필요한 다른 라이브러리들을 다운받을 필요가 없다는 뜻이다. 이를 통해 JS번들사이즈를 현저히 줄일 수 있다.
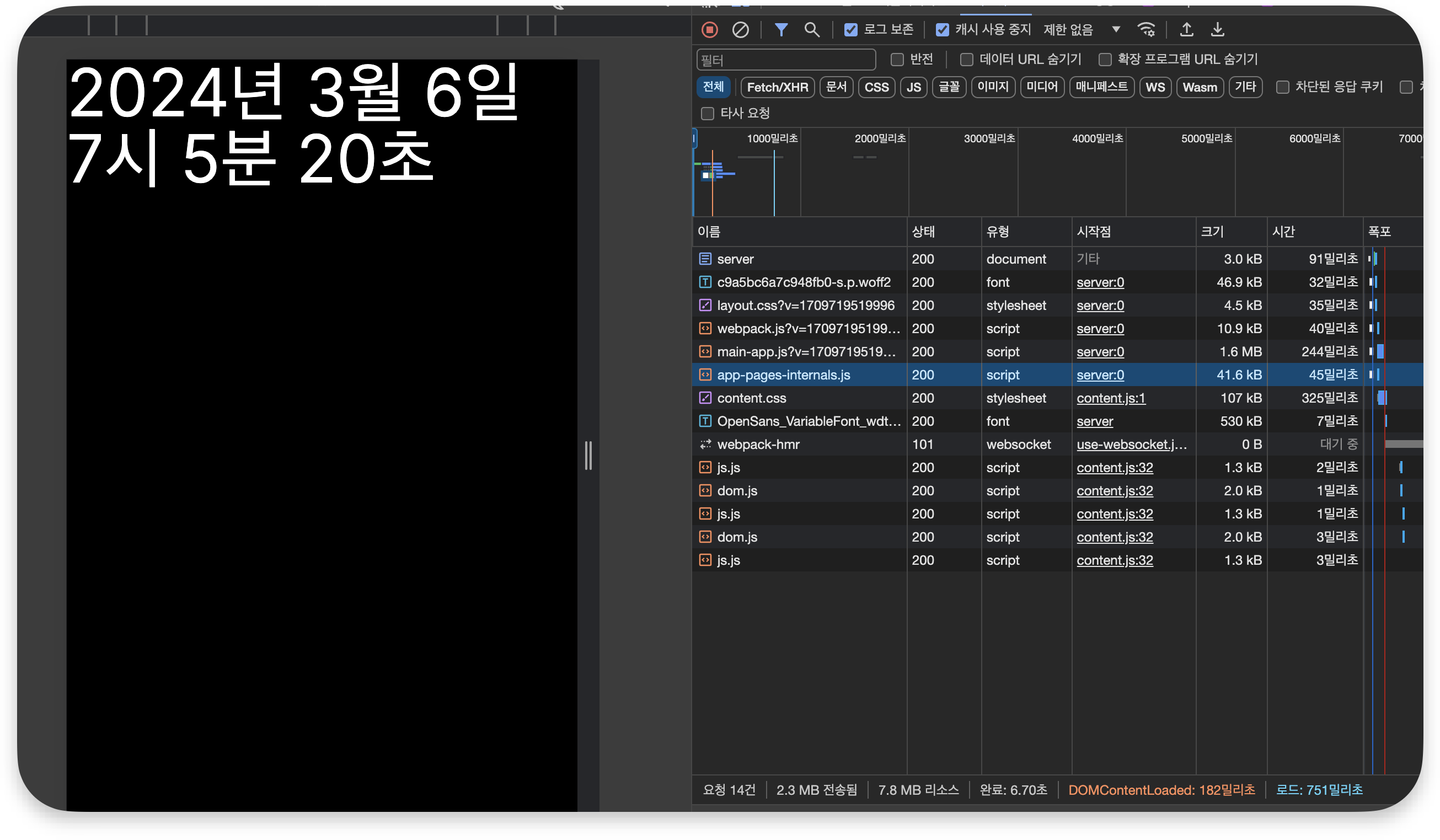
예시로 moment를 통해 date포맷팅을 해줬다고 할 때(일부로 번들 사이즈 큰 걸로 테스트 해봤어요ㅎ)
RSC로 렌더링 한 경우
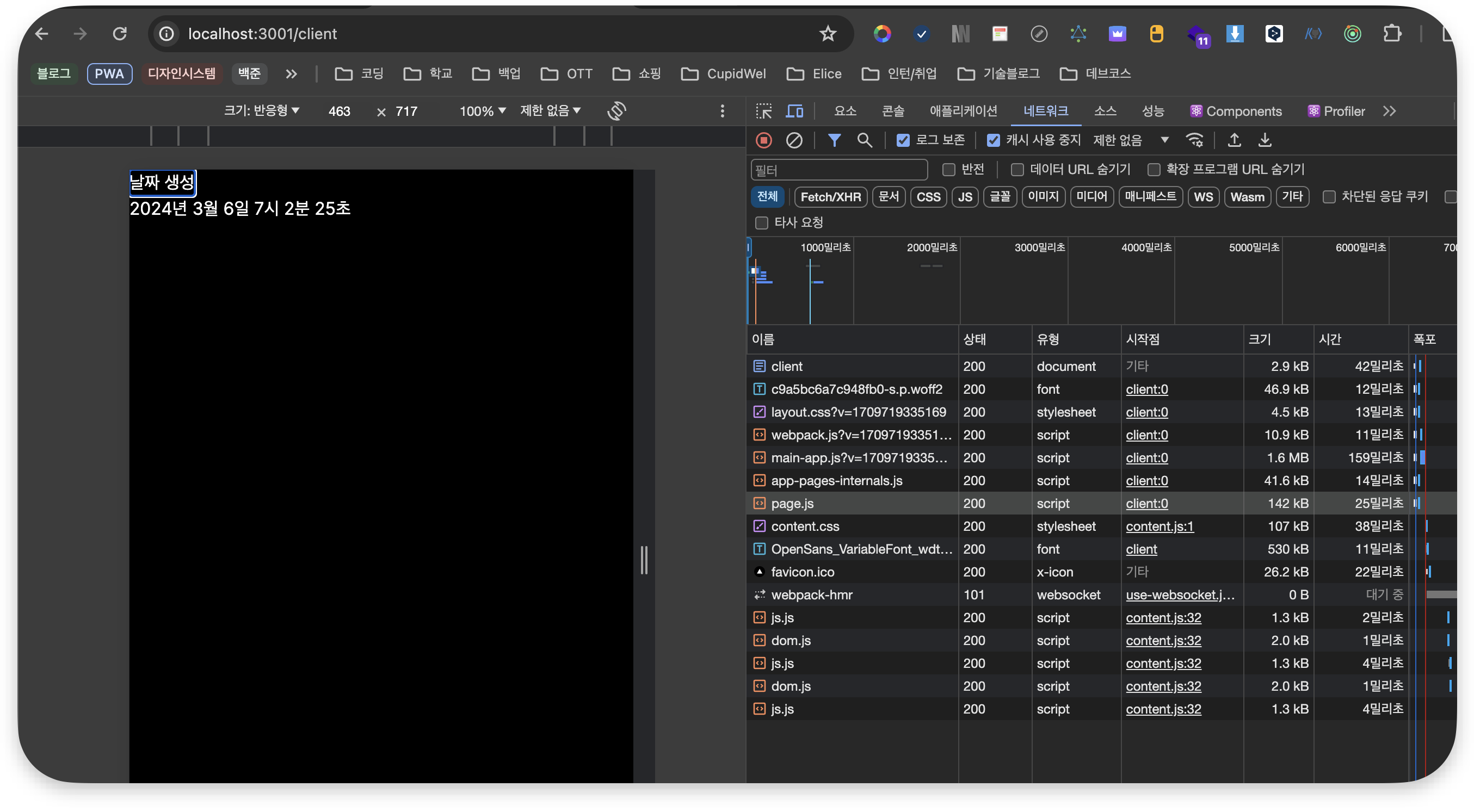
RCC로 렌더링 한 경우
RSC에서는 moment라이브러리가 Client로 넘어올 필요가 없다.
하지만 RCC에서는 Client에서 렌더링을 해야하기 때문에 moment도 함께 내려받아야 한다. 따라서 위의 사진 처럼 142kb의 page.js를 함께 다운받아야 한다.
이렇듯 여러 라이브러리를 쓸수록 유저 인터렉션이 없다면, RSC에서만 사용할 수 있고 이럴 경우는 큰 라이브러리를 사용해도 Client가 내려받는 JS 번들 사이즈는 동일하다(하지만 큰 라이브러리는 서버쪽 성능이 악깡버 해야겠지?ㅎ)
Automatic Code Splitting
원래 Code Splitting을 위해서는 React.Lazy나 dybamic Import를써야했다. 하지만 RSC에서 RCC를 import 할때는 실행하지 않고 표시만하고 넘어가기 때문에 부수적인 효과로 Code Splitting이 저절로 적용된다.
4. RSC의 단점
이해 러닝커브 극악…! 서버 지식 없으면 극극악…!!!!
그냥 핫 한 기술이니깐 찍먹해봐야지 ~~ 하고 들어가면 어떻게 동작하는지 이해가 안돼서 후두려맞기 딱 좋다… (Like me…)
결국 App Server
App server도 띄어야 하기 때문에 위의 SSR에서 생겼던 문제인 server관리가 필요해진다.(서버 로그도 봐야되고… 트래픽도 봐야되고…)
근데 이건 어짜피 프로젝트 내 누군가 해야할 일이었기 때문에 프로젝트 전체로 보면 단점은 아닌 것 같다(BE, 인프라 → FE로 이동한 느낌쓰?)
유저 인터렉션은 RCC에서 해야한다.
또 말하면 RSC는 서버에서”만” 실행된다.
즉, window같은 브라우저 속성에 접근,유저 인터렉션을 받아서 처리를 할 수 없다. 따라서 기존의 React로 사고하던 패러다임이 달라져 RSC가 해결하는 문제를 이해하고 ‘잘’ 쓰기 위해서는 설계도 ‘잘’ 해야한다.
Next에서는 유저 인터렉션 유무등 RSC와 RCC를 사용할때 권장 패턴이 있다. (맞다. 공부하고 고민할게 늘었다ㅎ)
아직 지원하는 라이브러리들이..ㅜ
신기술이니깐 어쩔 수 없지!
23.07.25 기준 RSC를 지원하는 라이브러리는 react/server-components/Discussions 에서 확인 할 수 있다.
우리의 TanstackQuery는 RSC는 안되고 RCC만 된다고 나와있는데 new QueryClient() 랑 HydrationBoundary 를 RSC에서 할 수 있는것 보면 문서가 업데이트 안된 듯 하다!
스스로 하는 Q&A
Q. RSC vs SSR
우선 SSR과 CSR의 차이는 모두 알 것이라고 생각한다. (가볍게 PASS~)
그러면 RSC와 SSR는 뭐가 다를까?
RSC와 SSR에서 server에 초점을 맞추지 말고 component와 rendering에 초점을 맞춰보자
RSC와 SSR은 관심사와 해결하고자 하는 문제가 다르다.
RSC는 react component를 server에서 실행시키는 것으로 server자원들을 사용할 수 있는 Component이다. RSC는 server에서 실행해서 나온 결과물을 RSC Payload형태로 반환한다.
SSR은 Server에서 html을 만들어 rendering하는 것이며 결과물로 HTML이 반환된다.
이 둘은 상위 개념이 아니라 서로 보완적인 개념이다.
즉, RSC도 SSR없이 CSR을 할 수 있고 SSR도 RCC가 할 수 있는 것이다. 둘의 차이를 알고 상황에 맞게 ‘잘’ 쓰는게 중요해보인다.
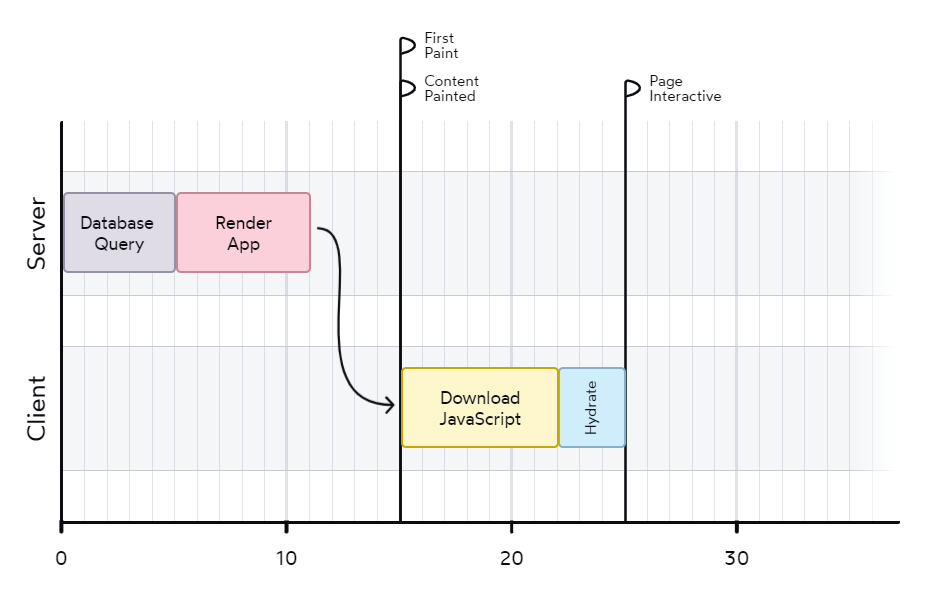
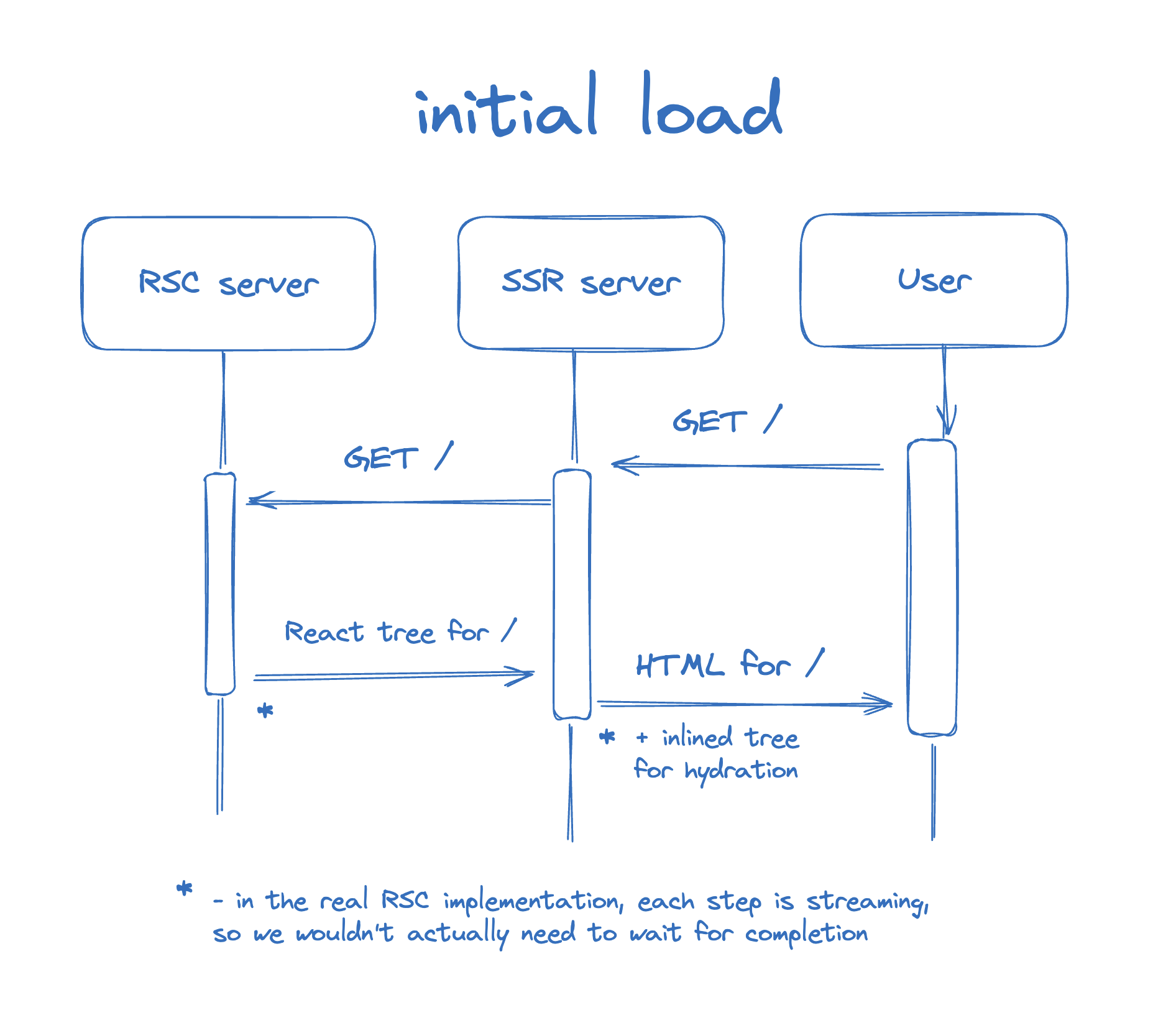
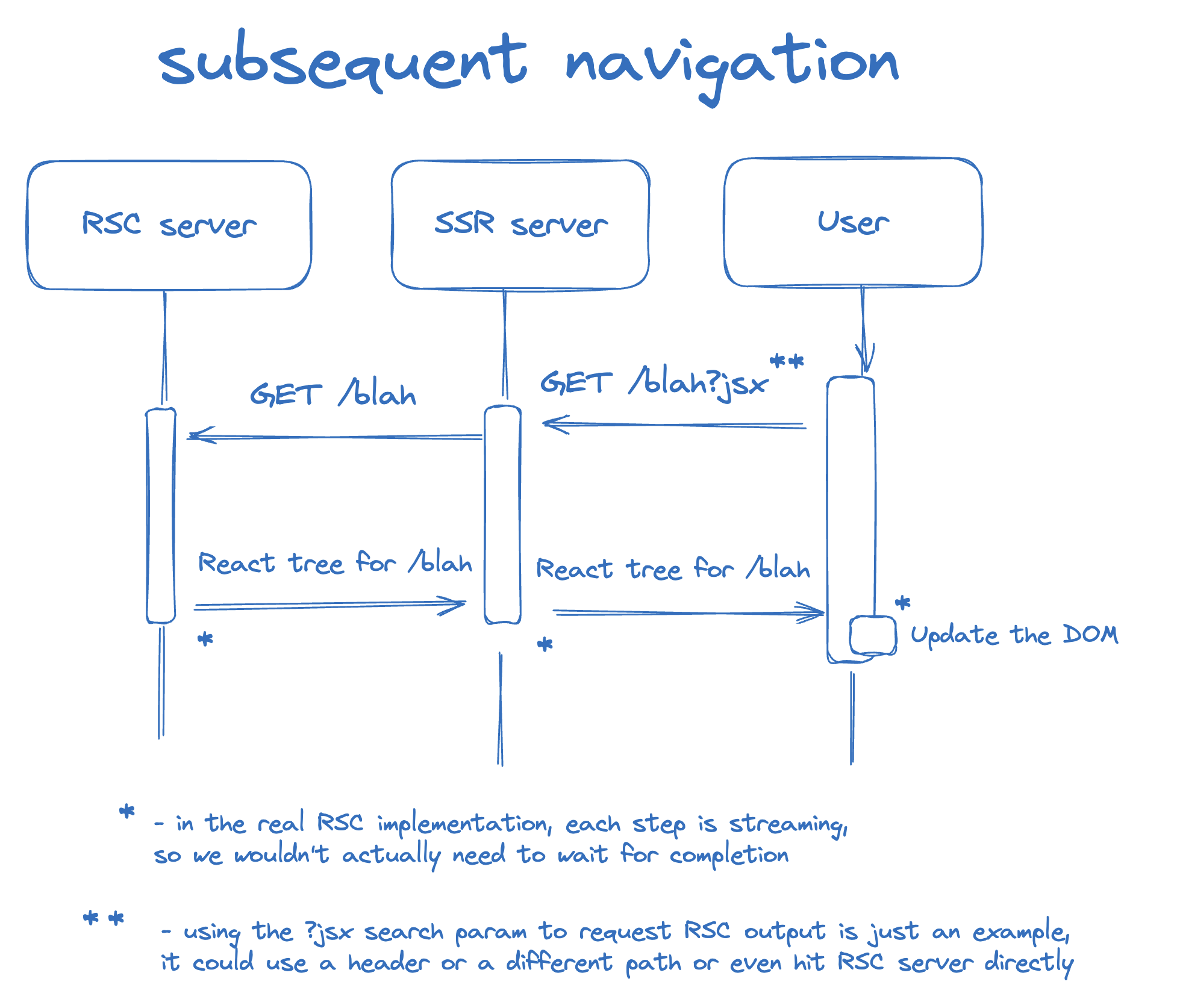
- Dan gaearon의 시각화 설명을 보면 곱씹어보자!!
첫번째 페이지를 로드하는상황
후속 탐색이 발생하는 상황
Q. RSC ≠ Next app routes
당연하게도 RSC와 Next는 다르다… 하지만 대부분 RSC 레퍼런스가 Next app routes로 되다.
왜냐하면 React의 이러한 신기술을 사용하기 위해서는 24/03/07 기준 Next에서만 사용할 수 있다ㅎ,,
그래서 너무 햇갈렸다!!! 이해한 것과 실제 테스트해본게 달라서ㅜㅜ Next공식문서와 함께 학습을 해야했다
결론은 RSC는 server에서 react component를 실행하고 결과물로 RSCPayload를 뱉는다. 이거를 server에서 렌더링하는것은 SEO최적화를 위해서 Next에서 채택한 방식일 뿐 RSC가 하는게 아니다!! (동일하게 RCC가 SSR되는 이유도 Next가 그런 방식을 채택했기 때문이다.)
⭐️Coming Soon⭐️
RSC에 대한 이해를 바탕으로 Next에서 RSC와 RCC가 렌더링 되는 방식과 원리를 탐구해봤다.
현재까지 내가 이해한 바를 시각화 하면 아래와 같다

참고
Next 공식문서 - RCC 렌더링 카카오 기술블로그 RSC 설명
Dan gaearon이 설명해주는 Suspense SSR 아키텍처
Dan gaearon이 설명해주는 Server components
댓글남기기